
Introducció
En aquesta primera edició del Big Data Congress s’hi han presentat tendències, reptes del sector i casos d’èxit reals tot donant una visió de l’estat de l’art actual del Big Data. Ha estat molt interessant veure com sectors molt diversos es recolzen de forma estratègica en el processat de grans volums de dades per extreure’n informació rellevant per a qui ha de dur a terme la presa de decisions.
El congrés, que ha durat dos dies, ha tingut una primera jornada més centrada en aspectes teòrics del Big Data mentre que a la segona jornada s’ha centrat més en usos pràctics i eines.

Big Data Congress Dia 1
Aquesta jornada ha començat amb exemples de l’aplicació del Big Data a la macro-estadística de tota la vida a més de definir el pla de ruta (roadmap) per arribar al Big Data en una organització. També s’ha parlat de les organitzacions dirigides per les dades, de les aplicacions que el Big Data té en àmbits com l’explotació de dades de clients o la gestió de ciutats. L’últim acte ha estat una taula rodona sobre els reptes actuals del Big Data.
A destacar el roadmap de l’IDC, molt interessant per posicionar una organització en quant a l’ús i gestió que fa de les dades en relació als beneficis del Big Data.
Un debat força present ha estat el de la mida que han de tenir les dades per considerar-se Big Data o bé Small Data. La conclusió de Marc Torrent ha estat la més convincent per nosaltres i és que, de fet, no importa si és big o small data, el que importa és que les decisions es basin en les teves dades. O dit d’una altra manera, el volum de les dades no té importància si no que el que importa és que la presa de decisions en una organització es basi en dades.
Com cada tecnologia, el Big Data també té els seus eslògans. Al Big Data Congress hem après que el Big Data es basa en la regla de les V:
-
Gran Volum de dades
-
Varietat de fonts i formats de les dades
-
Velocitat de processament
-
Veracitat de les dades
-
El resultat ha de ser informació de Valor
En resum, gairebé sembla que qualsevol paraula que comenci per V és un atribut vàlid del Big Data…
Destacar que els tres principals reptes del Big Data recalquen la immaduresa d’aquesta tecnologia. El primer repte és que ara mateix cada organització cal que es plantegi i determini quin valor específic pot extreure de les seves dades. El segon repte fa referència a la gestió d’aquestes dades tant pel què fa a l’obtenció com a l’emmagatzematge i processat. Finalment, el tercer repte és la manca de personal especialitzat.
Sobre les grans preguntes actuals sobre el Big Data s’ha reflexionat sobre varis temes. Com a nouvinguts al món del Big Data, ens han sobtat les dificultats inicials de definir l’estratègia Big Data en les organitzacions. Això ens fa pensar que en aquest moment el millor per a empreses que vulguin apostar per treure rendiment de les seves dades és recolzar-se en l’assessorament de consultors experts per tal d’enfocar correctament el problema des d’un inici i evitar inversions que acabin resultant improductives.
Una de les altres grans preguntes és com s’aplica la privacitat en el Big Data? Es respecta el dret a la intimitat? Sap realment quines dades està cedint i perquè les està cedint cada usuari? Tot això han sigut preguntes que s’han debatut i que, altra vegada, hem conclòs que la immaduresa d’aquest sector faci que estigui tot per concretar.
Sembla que tot i respectar en teoria la llei vigent, cada empresa aplica els seus estàndards de privacitat propis. Sovint acceptant les polítiques de privadesa de dues aplicacions d’una mateixa empresa no ens adonem que el creuament de la informació resultant del Big Data d’aquestes aplicacions pot resultar en vulneracions de la intimitat indirectes. Aquests tipus de casos són els que mai es contemplen a l’hora d’aplicar les polítiques.
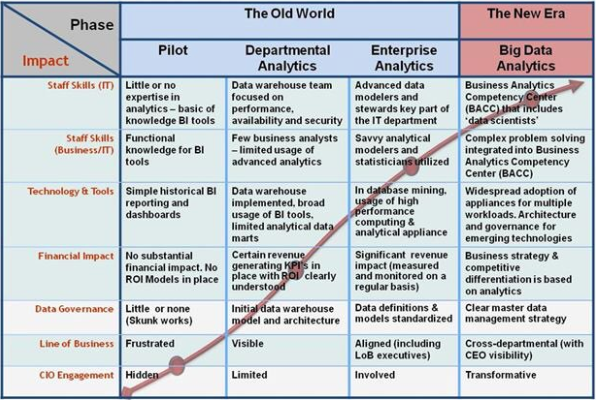
Big Data Congress Dia 2
Aquesta jornada ha començat amb Ricardo Baeza-Yates tornant a incidir en els desafiaments del Big Data, en aquest cas a la web. Tot seguit s’han comentat models analítics per millorar l’eficiència dels negocis i reduir el churn (usuaris que deixen d’utilitzar un servei). Tot seguit s’ha parlat d’innovació i startups del sector. L’última conferència l’ha dut a terme el responsable del projecte Apache Flink, una nova eina de Big Data.
Ens ha sorprès l’enorme quantitat de dades que gestionen empreses amb moltíssims usuaris que cada dia generen milers de teras de dades que després han de ser analitzades per les eines de Big Data. Daniel Villatoro ha fet una presentació molt graciosa on destacava els grans errors que un Data Scientist mai pot permetre’s fer i que, si no es para atenció, és fàcil que passin.
La forma en què es comunica el coneixement extret del Big Data, de vegades trivial i de vegades complex, ha estat debatut per Alberto González i Miguel Nieto des de dues perspectives, la d’un estudi macroeconòmic i social i la de plasmar diferents tipus de dades en mapes.
També interesant la introducció del concepte Smart Data. Consistent en enfocar la recol·lecció i anàlisi de les dades principalment en obtenir el major valor possible per a l’organització, i no tant en la acumulació massiva d’aquesta.
Oracle ha presentat la seva solució Big Data de Business Intelligence i Analytics, enfocada a l’obtenció de valor per l’empresa. Aquesta eina disminueix a mínims el temps de desenvolupament i integració del projecte. Un producte que sembla molt interessant, igual que la filosofia modular de totes les funcionalitats de què disposa. El que no ha estat tant interessant ha sigut l’exemple plantejat on s’havia utilitzat la plataforma Big Data per acabar deduint que les pimes paguen nòmines a treballadors que tenen comptes en d’altres bancs.
Del Barcelona Supercomputing Center s’ha fet la presentació d’Aloja, un projecte pensat per facilitar la configuració dels centenars de paràmetres de les eines de Big Data a través del feedback del performance per cada cas d’ús. Per obtenir bons rendiments no serveix configurar una eina, en aquest cas Hadoop, segons la màquina on s’instal·la. També cal tenir en compte factors externs com l’algorisme que s’està executant, l’origen i destí de les dades, etc. Com sempre es tracta de detectar on és el coll d’ampolla i optimitzar la configuració per evitar-los.
La presentació d’Apache Flink ha estat bona. Es tracta d’una eina que es basa en el processat continu d’un flux de dades, en contraposició a les eines més populars que fan el processament tot alternant passos d’obtenció de dades amb passos de processament. Sembla que en breu pot plantejar-se com a bona alternativa segons el cas d’ús, i de fet, ja s’està utilitzant en alguns entorns de producció.
Conclusions
El Big Data (es pot traduir com macrodades instantànies?) és una tecnologia que es troba en un estat d’Early Adopters, o adoptadors primerencs. Ara mateix manca d’estàndards i les bones pràctiques són a nivell individual o bé organitzatiu. Això però, no vol dir que no pugui aportar valor, ans al contrari: el Big Data és ja avui una eina imprescindible per a moltes organitzacions que s’hi basen per optimitzar recursos i inversions.
La manca de personal qualificat també ha estat comentada de forma continua així que especialitzar-se en el Big Data sembla que a dia d’avui és una bona aposta per trobar una bona feina.







