Impresiones del Big Data Congress Barcelona 2015

Introducción
En esta primera edición del Big Data Congress se han presentado tendencias, retos del sector y casos de éxito reales dando una visión del estado actual del Big Data. Ha sido muy interesante ver como sectores muy diversos se apoyan de forma estratégica en el procesado de grandes volúmenes de datos para extraer información relevante para quien lleve a cabo la toma de decisiones.
El congreso, que ha durado dos días, ha tenido una primera jornada más centrada en aspectos teóricos del Big Data mientras que la segunda jornada se ha centrado más en usos prácticos y herramientas.

Big Data Congress Día 1
Esta jornada ha empezado con ejemplos de la aplicación del Big Data a la macro-estadística de toda la vida además de definir el plan de ruta (roadmap) para llegar al Big Data de una organización. También se ha hablado de las organizaciones dirigidas por los datos, de las aplicaciones que el Big Data tiene en ámbitos como la explotación de datos de clientes o la gestión de ciudades. El último acto ha sido una mesa redonda sobre los retos actuales del Big Data.
A destacar el roadmap del IDC, muy interesante para posicionar una organización en cuanto al uso y gestión que hace de los datos en relación a los beneficions del Big Data.
Un debate bastante presente ha sido el del tamaño que tienen que tener los datos para considerarse Big Data o Small Data. La conclusión de Marc Torrent ha sido la más convincente para nosotros, y es que, de hecho, no importa si es big o small data, lo que importa es que las decisiones se basen en tus datos. O dicho de otra manera, el volumen de los datos no tiene importancia ya que lo que realmente importa es que la toma de decisiones en una organización se base en datos.
Como cada tecnología, el Big Data tiene también sus eslóganes. En el Big Data Congress hemos aprendido que el Big Data se basa en la regla de las V:
-
Gran Volumen de datos
-
Variedad de fuentes y formatos de los datos
-
Velocidad de procesamiento
-
Veracidad de los datos
-
El resultado tiene que ser información de Valor
En resumen, casi parece que cualquier parabla que empiece por V es un atributo válido del Big Data...
Destacar que los tres principales retos del Big Data recalcan la inmadurez de esta tecnología. El primer reto es que, ahora mismo, cada organización necesita que se plantee y determine qué valor específico puede extraer de sus datos. El segundo reto hace referencia a la gestión de estos datos tanto a nivel de obtención como de almacenamiento y procesamiento. Finalmente, el tercer reto es la falta de personal especializado.
Sobre las grandes preguntas actuales sobre el Big Data, se ha reflexionado sobre varios temas. Como recién llegados al mundo del Big Data, nos han sorprendido las dificultades iniciales de definir la estrategia Big Data en las organizaciones. Esto nos hace pensar que en este momento lo mejor para empresas que quieran apostar por sacar rendimiento de sus datos es apoyarse en el asesoramiento de consultores expertos con tal de enfocar correctamente el problema desde un inicio y evitar inversiones que acaben resultando improductivas.
Una de las otras grandes preguntas es ¿Cómo se aplica la privacidad en el Big Data? ¿Se respeta el derecho a la intimidad? ¿Sabe realmente qué datos está cediendo y para qué las está cediendo cada usuario? Todo esto han sido preguntas que se han debatido y que, de nuevo, hemos concluido que la inmadurez de este sector haga que esté todo por concretar.
Parece que a pesar de respetar en teoría la ley vigente, cada empresa aplica sus propios estándares de privacidad propios. Frecuentemente, aceptando las políticas de privacidad de dos aplicaciones de una misma empresa no nos estamos dando cuenta de que el cruce de la información resultante del Big Data de estas aplicaciones puede resultar en vulneraciones de la intimidad indirectas. Estos tipos de casos son los que nunca se contemplan a la hora de aplicar las políticas.
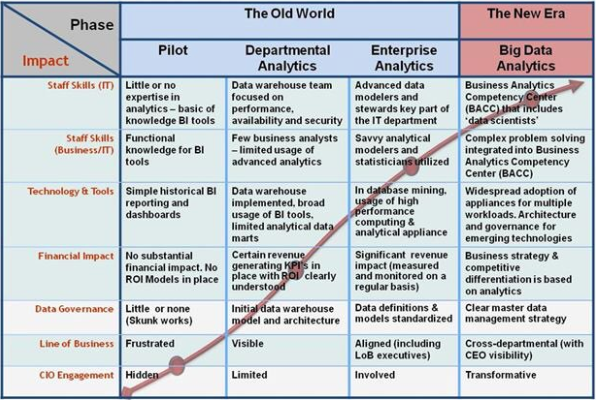
Big Data Congress Día 2
Esta jornada ha empezado con Ricardo Baeza-Yates volviendo a incidir en los desafíos del Big Data, en este caso en la web. Seguidamente se han comentado modelos analíticos para mejorar la eficiencia de los negocios y reducir el churn (usuarios que dejan de utilizar un servicio). También se ha hablado de inovación y startups del sector. La última conferencia ha ido a cargo de los responsables del proyecto Apache Flink, una nueva herramienta de Big Data.
Nos ha sorprendido la enorme cantidad de datos que gestionan empresas con muchísimos usuarios que cada día generan miles de teras de datos que después tienen que ser analizados por las herramientas del Big Data. Daniel Villatoro ha hecho una presentación muy entretenida en la que destacaba los grandes errores que un Data Scientist nunca puede permitirse hacer y que, si no se presta atención, es fácil que ocurran.
La forma en que se comunica el conocimiento extraído del Big Data, a veces trivial y a veces complejo, ha sido debatido por Alberto González y Miguel Nieto desde dos perspectivas, la de un estudio macroeconómico y social y la de plasmar diferentes tipos de datos en mapas.
También interesante ha sido la introducción del concepto Smart Data. Consistente en enfocar la recolección y análisis de los datos principalmente para obtener el mayor valor posible para la organización, y no tanto en la acumulación masiva de esta.
Oracle ha presentado su solución Big Data de Business Intelligence y Analytics, enfocada a la obtención de valor para la empresa. Esta herramienta disminuye a mínimos el tiempo de desarrollo e integración del proyecto. Un producto que parece muy interesante, igual que la filosofía modular de todas las funcionalidades de que dispone. Lo que no ha sido tan interesante ha sido el ejemplo planteado en el que se había utilizado la plataforma Big Data para acabar deduciendo que las pymes pagan nóminas a trabajadores que tienen cuentas en otros bancos.
Del Barcelona Supercomputing Center se ha hecho la presentación de Aloja, un proyecto pensado para facilitar la configuración de los centenares de parámetros de las herramientas de Big Data a través del feedback de la performance para cada caso de uso. Para obtener buenos rendimientos no sirve configurar una herramienta, en este caso Hadoop, según la máquina en la que se instala. También hay que tener en cuenta factores externos como el algorismo que se está ejecutando, el origen y destino de los datos, etc. Como siempre, se trata de detectar dónde se encuentra el cuello de botella y optimizar la configuración para evitarlos.
La presentación de Apache Flink ha sido buena. Se trata de una herramienta que se basa en el procesado continuo de un flujo de datos, en contraposición a las herramientas más populares que hacen el procesamiento alternando pasos de obtención de datos con pasos de procesamiento. Parece que en breve puede plantearse como una buena alternativa según el caso de uso, y de hecho, ya se está utilizando en algunos entornos de producción.
Conclusiones
El Big Data (¿se puede traducir como macrodatos instantáneos?) es una tecnología que se encuentra en un estado de Early Adopters, o adoptadores primerizos. Ahora mismo le faltan estándares y las buenas prácticas son a nivel individual o organizativo. A pesar de esto, no quiere decir que no puedan aportar valor, todo lo contrario: el Big Data es ya hoy una herramienta imprescindible para muchas organizaciones que se basan en ella para optimizar recursos e inversiones.
La falta de personal cualificado también ha estado comentada de forma continuada. Así que especializarse en el Big Data parece que a día de hoy es una buena apuesta para encontrar un buen trabajo.







